In Short: Microsoft Is Building Its Own AI Infrastructure
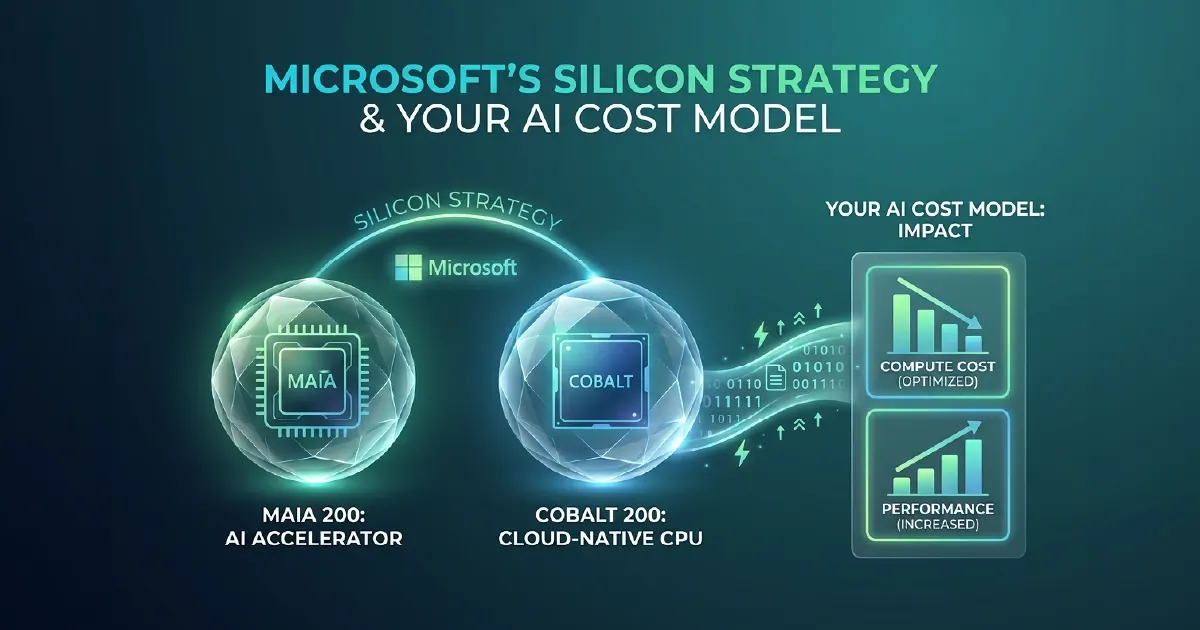
Maia 200 and Cobalt 200 are Microsoft's custom silicon chips for Azure infrastructure. Maia 200 is an AI accelerator designed for training and inference of large language models. Cobalt 200 is an ARM-based processor for general Azure compute workloads.
For organisations using Azure AI, Microsoft Fabric, and Azure OpenAI, these chips matter for one reason: they are Microsoft's mechanism for reducing the cost of AI compute over time. As Maia 200 production scales, the economics of running AI inference on Azure will improve - and those improved economics will eventually translate into lower prices for customers. Understanding the silicon strategy helps you build AI cost models that account for expected price trajectories, not just today's pricing.
What Maia 200 Is
Maia 200 is Microsoft's custom AI accelerator chip, built specifically for the matrix multiplication operations that dominate large language model training and inference. It is purpose-built for the workload profile of Azure OpenAI - high-throughput inference at datacenter scale - rather than being a general-purpose GPU adapted for AI work.
The business case for Maia 200 is straightforward: at the volume of AI inference Microsoft runs for Azure OpenAI across millions of enterprise customers, reducing dependency on third-party GPU supply chains (Nvidia H100s, H200s) directly improves Microsoft's economics. Those improved economics translate first into better margins and then, as production scales further, into lower customer prices.
Maia 200 is an infrastructure chip used inside Azure datacenters. Its impact on customers is indirect - through AI service pricing over time - rather than through anything customers deploy themselves.
What Cobalt 200 Is
Cobalt 200 is Microsoft's ARM-based general compute chip, used for Azure virtual machine workloads that do not require AI acceleration. It follows the pattern established by Amazon's Graviton and Google's Axion - hyperscaler-designed ARM processors that reduce dependency on Intel and AMD CPUs for standard compute.
For Fabric customers, Cobalt 200 is relevant to the general compute components of Fabric workloads: Spark cluster nodes, SQL serverless compute, and the orchestration infrastructure that runs pipelines and notebooks. As Cobalt 200-backed compute becomes default for standard Azure VMs, Fabric capacity-based pricing benefits indirectly from improved cost efficiency at the infrastructure layer.
What This Means for Your AI Cost Model
The most important implication of Microsoft's silicon investment is directional: AI inference costs on Azure will decline over the next two to three years.
Do not lock long-term AI infrastructure cost assumptions at today's prices. AI use cases that are economically marginal today - too expensive to run at scale given current token pricing - may become clearly viable by 2027-2028 as Maia 200 production scales and inference costs decline. Build AI business cases that are viable at today's pricing but project improving economics over a 3-year horizon.
Evaluate capacity commitment timing carefully. Azure Reserved Capacity agreements lock in current pricing for cost certainty. In a declining price environment, shorter commitment windows preserve the ability to benefit from price reductions as they materialise. This is different from conventional wisdom for stable compute pricing, where longer commitments always pay off.
Model tiering benefits from declining costs asymmetrically. Cheaper model tiers (GPT-4o mini, Phi-4 on-device) will decline in cost fastest as Maia 200 economics improve. Premium reasoning model tiers will decline more slowly. The cost advantage of model tiering - using cheaper models for routine tasks and premium models only when needed - will therefore remain significant even as overall prices fall.
The Competitive Context
Maia 200 and Cobalt 200 position Microsoft alongside Google (TPUs, Axion) and Amazon (Trainium, Graviton) as hyperscalers with comprehensive custom silicon programmes. All three are converging on a model where they control their own compute economics from silicon upward - reducing dependency on Nvidia and Intel and capturing the economics of the AI infrastructure layer.
For customers, the implication is that AI infrastructure economics will become increasingly specific to each hyperscaler's silicon roadmap rather than tracking a common market price. Organisations deeply committed to a single hyperscaler will benefit from that provider's silicon efficiency improvements. Multi-cloud AI workloads need to be modelled separately for each platform.
The Timeline for Customer Impact
Maia 200 is in production deployment within Azure datacenters now. Its impact on Azure OpenAI pricing will be gradual - Microsoft will absorb improved economics to improve margins before passing savings to customers.
The most likely mechanism is new model tiers appearing at lower price points as Maia 200 production scales - faster, cheaper variants of existing capability levels - rather than existing model prices being reduced in step changes. This mirrors how Azure compute pricing has historically evolved.
When building AI cost projections for 2026-2028, a reasonable assumption is that the inference cost per token for a given capability level will be 30-50% lower by 2028 than today, driven by Maia 200 economics and ongoing model efficiency improvements. AI applications that are marginal at current pricing should be evaluated against this declining cost trajectory before being shelved as uneconomical.