In Short: What actually is the Osmos acquisition and autonomous engineering ?
Microsoft acquired Osmos in January 2026 to embed autonomous data engineering directly into Microsoft Fabric. The goal is straightforward: reduce the amount of time data teams spend preparing data and increase the time they spend using it.
What Problem Was Microsoft Trying to Solve?
The most consistent complaint across data engineering teams is not a shortage of tools. It is that the tools require constant manual intervention.
Data arrives in the wrong format. Schemas change unexpectedly. Pipeline logic written six months ago breaks when the source system updates. The result is that engineers spend a disproportionate share of their time on maintenance: rather than analysis, insight, and business value.
Microsoft's own framing of the Osmos acquisition identified this directly: "many teams spend most of their time preparing data instead of analysing it."
The acquisition is an attempt to change that ratio.
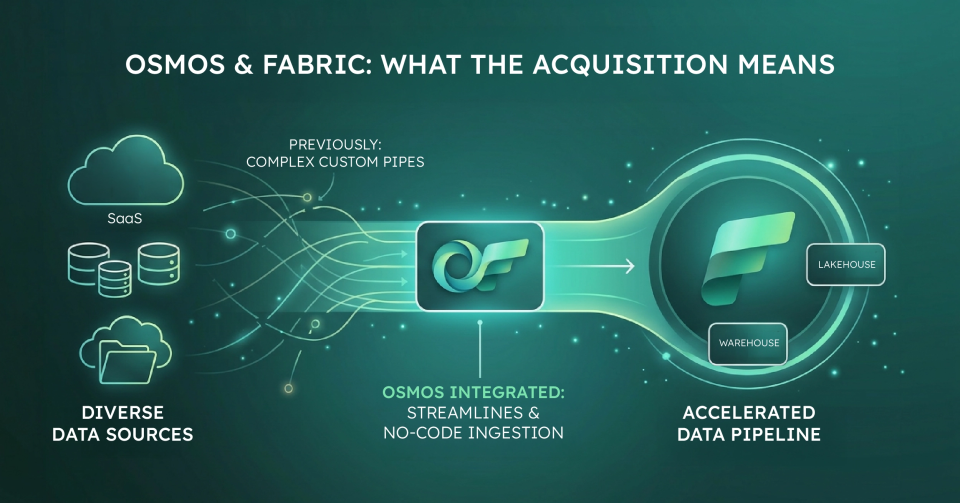
What Is Osmos?
Osmos is an agentic AI data engineering platform. Its core capability is converting raw, unstructured, or inconsistently formatted data into analytics-ready assets, without requiring manual transformation logic to be written and maintained for every source.
The key word is agentic. Osmos does not just assist with data preparation. It takes on preparation tasks autonomously, monitors for drift, and adapts when upstream sources changes.
Following the acquisition, the Osmos team joined Microsoft's Fabric engineering organisation. The technology is being integrated into OneLake as the data preparation layer. This means raw data lands in OneLake and Osmos-derived capability handles the transformation into usable form.
What Changes for Data Engineering Teams in Fabric?
The practical implications are still emerging as the integration develops. Based on Microsoft's stated direction, the expected changes are:
1. Reduced Pipeline Maintenance Overhead Autonomous agents monitor data quality and schema changes, flagging or handling drift before it breaks downstream processes.
2. Faster Onboarding of New Data Sources Rather than writing transformation logic from scratch for each new source, teams describe the output format and the agent handles the mapping.
3. Lower Barrier for Non-Engineering Teams Business analysts and data stewards can onboard data sources without needing to write or maintain engineering code, reducing the bottleneck on specialist resources.
4. More Reliable Analytics Outputs When data preparation is monitored and adapted automatically, the downstream reports and models it feeds become more consistently accurate.
Where Does This Fit in the Broader Fabric Architecture?
OneLake is the data foundation for Fabric: a single logical lake that all Fabric workloads read from and write to. Osmos-derived capability sits at the ingestion layer: data arrives in OneLake, and autonomous engineering logic converts it into the structured, governed assets that Data Engineering, Data Warehousing, Power BI, and Data Agents consume.
This is strategically significant. Microsoft is not positioning autonomous data engineering as a standalone feature. It is embedding it as infrastructure: the layer that makes everything else work reliably at scale.
What Is the Strategic Point Most Organisations Miss?
Autonomous data engineering does not eliminate the need for data engineers. It changes what they focus on.
The shift is from reactive maintenance, such as fixing pipelines that break or reformatting data that arrives in unexpected shapes, to proactive design: defining standards, setting quality thresholds, and governing how autonomous agents operate.
Organisations that treat Osmos-derived capability as a way to reduce headcount will miss the point. Organisations that treat it as a way to redirect engineering effort toward higher-value work will gain a meaningful advantage.
Who Will Benefit Most From This Integration?
This development is most relevant for organisations that:
- Run large volumes of diverse data sources with varying schema stability
- Have data engineering teams spending significant time on pipeline maintenance
- Are building toward an AI-ready data estate in Microsoft Fabric
- Want to reduce the gap between data arrival and data availability for analytics
Why work with Solv Systems on Autonomous Engineering ?
At Solv Systems, we implement autonomous data engineering to accelerate your path from raw data to insight.
Strategy Before Build
We help you define the right balance between automated prep and human governance for your specific use cases.
Patterns That Scale
We design resilient data architectures that leverage autonomous capabilities without creating "black box" logic.
Proactive Engineering
We stay ahead of the Osmos integration roadmap to ensure your systems are ready for the latest autonomous features.
Governance and Adoption
We ensure that autonomous processes operate within your established data quality and security frameworks.


